Issue
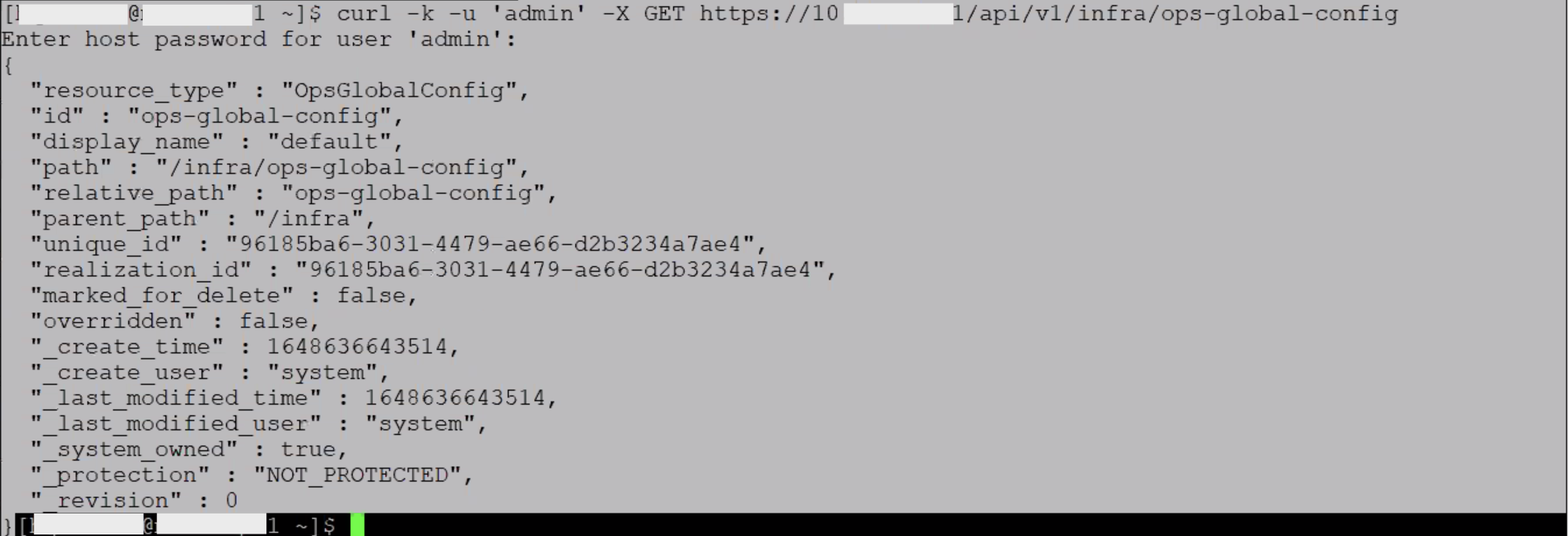
A customer writes me an email asking for help because two Edge nodes in his NSX-T infrastructure had the following critical error (as shown in the picture below):
"Edge VM Present In NSX Inventory Not Present In vCenter"

Solution
This error message, as we can see from the this link was introduced in version 3.2.1.
The customer has already tried to verify what is indicated in the "Recommended Action" and found that the vm-id is not modified, and the Edge VMs are still in the vCenter Inventory.
Asking if he had made any changes, he replies that the only change made was at the vCenter level to update the expired Machine Cert, and that the certificate was revalidated by NSX-T (indeed the communication between the NSX-T system and the vCenter was showing no errors).
In summary, the Edge VMs were still in inventory, nobody had changed the vm-id, the only thing that had changed was the certificate in vCenter.
The customer fixed it himself on the first attempt, by restarting the cluster appliance the VIP was pointing to. By doing so, when the VIP was switched to another appliance of the NSX Manager cluster, the message resolved itself.
As a second attempt, if the first didn't work, after verifying correctly what is indicated in the "Recommended actions" would be to "Redeploy an NSX Edge VM Appliance" if the edge is no longer connected to NSX Manager; otherwise to replace it inside the Cluster (one by one) as indicated in "Replace an NSX Edge Transport Node Using the NSX Manager UI"
That's it.