Issue
New day, new issue :-)
I'm not able to traceflow traffic between two VMs plugged on VLAN backed segment managed by NSX-T 3.2.0.1, obtaining the following error message:
Traceflow request failed. The request might be cancelled because it took more time than normal. Please retry.
Error Message: Error: Traceflow intent /infra/traceflows/<UID> realized on enforcement point /infra/sites/default/enforcement-points/default with error Traceflow on VLAN logical port LogicalPort/<UID> requires INT (In-band Network Telemetry) to be enabled (Error code: 500060)

So, why it doesn't work??
I tried running the indicated REST API call "PUT /api/v1/global-configs/IntGlobalConfig" to enable In-band Network Telemetry (INT). Without success !!!
Solution
I found the solution by googling "nsx-t (In-band Network Telemetry) to be enabled (Error code: 500060)", and a post "NSX-T Traffic Analysis Traceflow fails" by "Brian Knutsson" came out. The post explain how to enable the Traceflow in NSX-T 3.2 for vlan backed. Here are the steps performed in my infrastructure.
I made the follofing REST call:
curl -k -u 'admin' -X GET https://<NSX Manager IP of FQDN>/api/v1/infra/ops-global-config
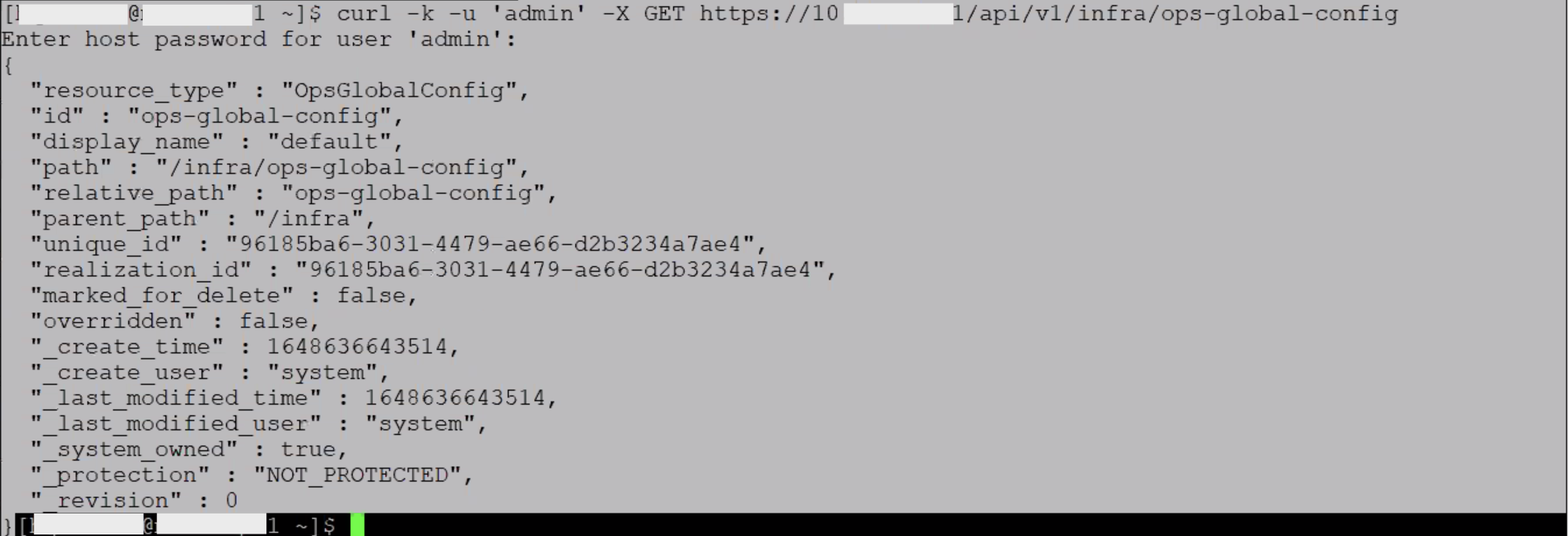
curl -k -u 'admin' -X PUT -H "Content-Type: application/json" -d
'{
"display_name": "ops-global-config",
"in_band_network_telementry": {
"dscp_value": 2,
"indicator_type": "DSCP_VALUE"
},
"path": "/infra/ops-global-config",
"relative_path": "ops-global-config",
"_revision": 0
}'
https://<NSX Manager IP of FQDN>/policy/api/v1/infra/ops-global-config


That's it.