Issue
One month ago, I came across this. After a disaster recovery test performed via SRM, we encountered the following error "Reduced availability without rebuild" for 27 objects, we tried to click "repair object immediately" without success.
There are no resync objects in progress.
The source and target infrastructure consists of two VCF 5.X environment based on vSAN file system, where Site Recovery Manager is used to replicate VMs.
This issue reduce the Health score rate to 60%.

Issue Clarification:
Customer has 27 objects all using the same policy showing a reduced availably with no rebuild
Issue Verification:
We verified that the cluster has 27 objects that are in reduced availability with no rebuild.
Cause Identification:
We found that the customer is using a ftt2 policy with force provisioning for these objects.
Cause Justification:
As we see in the chart on https://docs.vmware.com/en/VMware-Cloud-on-AWS/services/com.vmware.vmc-aws-operations/GUID-EDBB551B-51B0-421B-9C44-6ECB66ED660B.html
In order to satisfy a ftt2 policy we will need 5 hosts.

Force provisioning:
If the option is set to Yes, the object is provisioned even if the Primary level of failures to tolerate, Number of disk stripes per object, and Flash read cache reservation policies specified in the storage policy cannot be satisfied by the datastore. Use this parameter in bootstrapping scenarios and during an outage when standard provisioning is no longer possible.
The default No is acceptable for most production environments. vSAN fails to provision a virtual machine when the policy requirements are not met, but it successfully creates the user-defined storage policy.
Solution Recommendation:
Change the policy to match the current host configuration or add a host to match the policy
Solution Justification:
Once the policy is set to match the cluster the objects will be compliant and will no longer be in the reduced availability with no rebuild status.

I also changed, created a new policy, re-applied the storage policy on those VMs/Objects without success.
Solution
We have been able to solved the issue performing the following steps:
Short Answer
- Create a Protection Group and a new Recovery Plan on SRM;
- Check that the VMs(/objects with the issue) were correctly replicated (in sync) with the target;
- Migrate the VMs(/objects with the issue) to the new Protection Group;
- Check the configuration of the VMs with the Edit Setting (no disks connected);
- Active the Recovery Plan test and the VMs should turned on correctly;
- Check again via Edit Settings whether the disks are present, and indeed they are correctly attached.
- Verify in "vSAN Object Health" there are no more objects in "reduced availability with no rebuild".
- Perform the test clean up and migrate the VMs back to the original Protection Group.
- Re-check the configuration of the VMs with the Edit Setting (no disks connected, maybe they are managed by SRM and connected when required).
- Perform a double check and make sure everything is working fine.
Long Answer (with screenshots and details)
-
Create a Protection Group and a new Recovery Plan on SRM:
- Connect to the Site Recovery Manager where the VM with the error are present
- Create a new PG; in my case I named it "BA-Test-vSAN-Issue"
- Creare a new RP; in my case I named it "TEST-BA-MGMT_RecoveryPlan"
- In "Virtual Objects" we can see that the VM is in the "Reduced availability without rebuild" state
-
Check that the VMs(/objects with the issue) were correctly replicated (in sync) with the target:
- Check on the current PG that the virtual machine is synchronized

-
Migrate the VMs(/objects with the issue) to the new Protection Group (BA-Test-vSAN-Issue):
- Edit the original PG
- Unflag the VM (to remove it from the PG) - Edit the new PG and Add the VM
- Edit the new PG and Add the VM

-
Check the configuration of the VMs with the Edit Setting (no disks connected):
- Edit Settings on the VM and check it
-
Active the Recovery Plan test and the VMs should turned on correctly:
- The virtual machine is synchronized
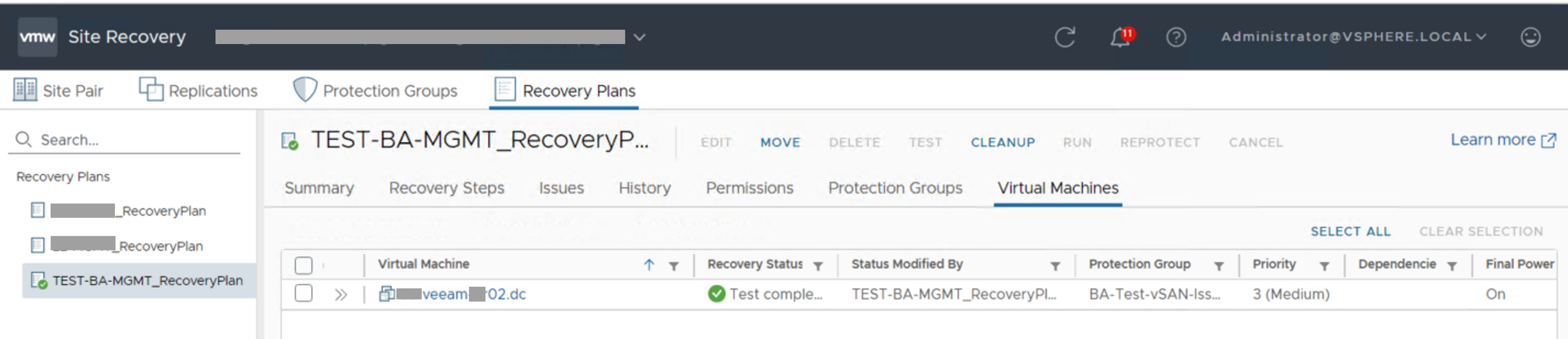
- Go to the new Recovery Plan (in my case "TEST-BA-MGMT_RecoveryPlan") and activate it



-
Check again via Edit Settings whether the disks are present, and indeed they are correctly attached:
- When the RP is in progress and the VM is turning on, check the presence of the disk on the VM via Edit Settings
- Wait untill the test is completed
- Check that the machine is up and running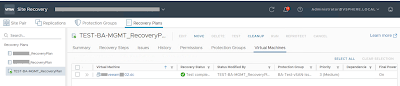

-
Verify in "vSAN Object Health" there are no more objects in "reduced availability with no rebuild":
- Verify that the VM is no longer present in the object list with "reduced availability with no rebuild"
-
Perform the test clean up and migrate the VMs back to the original Protection Group:
- As soon as the Cleanup procedure is completed ... - ... and the VM is in Ready state, move it back to the original Protection Group
- ... and the VM is in Ready state, move it back to the original Protection Group

-
Re-check the configuration of the VMs with the Edit Setting (no disks connected, maybe they are managed by SRM and connected when required):
-
Perform a double check and make sure everything is working fine:
- Once you have performed the above steps for all the VMs with the problem, you should see the "Cluster Health score" at 100% as shown in the image below


















Reactivating the entire Recovery Plan would probably have solved the "Reduced availability without rebuild" issue.
However, this approach is more granular and aim to solve the problem of the single VM, without negatively impacting the performance of the entire target environment. It is not mandatory to proceed one VM at a time.
Obviously, it is possible to migrate multiple VMs simultaneously into the temporary Protection Group, power them on simultaneously via recovery plan and then bring them back into the original protection group once the problem has been resolved.
That's it.










